汉王PDF OCR是一个带有 PDF 文件处理功能的 OCR 软件;具有识别正确率高,识别速度快的特点。本站提供汉王PDF OCR简体中文版最新官方免费下载。
汉王ocr识别软件有批量处理功能,避免了单页处理的麻烦;支持处理灰度、彩色、黑白三种色彩的BMP、TIF、JPG、PDF多种格式的图像文件;可识别简体、繁体和英文三种语言;具有简单易用的表格识别功能;具有TXT、RTF、HTM和XLS多种输出格式,并有所见即所得的版面还原功能。
新增打开与识别PDF文件功能,支持文字型PDF的直接转换和图像型PDF的OCR识别,既可以采用OCR的方式将PDF文件转换为可编辑文档,也可以采用格式转换的方式直接转换文字型PDF文件为RTF文件或文本文件。
汉王pdf ocr怎么用
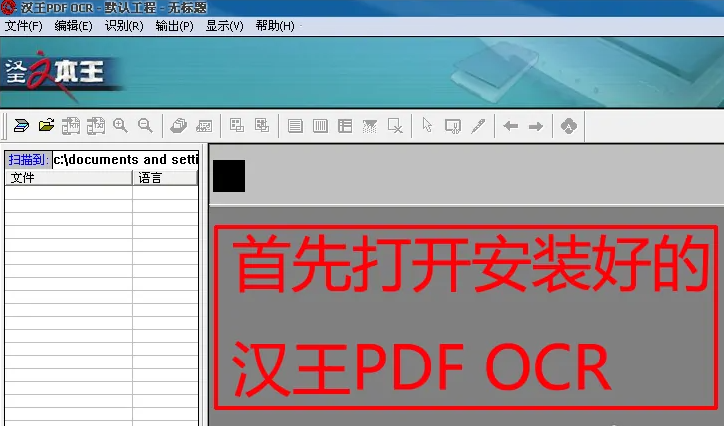
1、打开安装好的汉王PDF OCR。
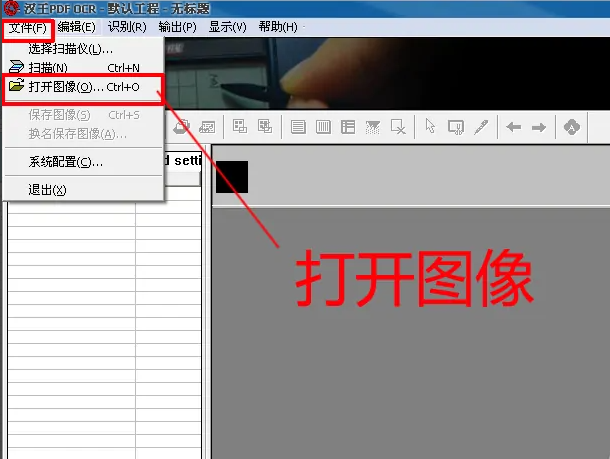
2、依次点击“文件”-“图像”(或直接按快捷键ctrl+O)。
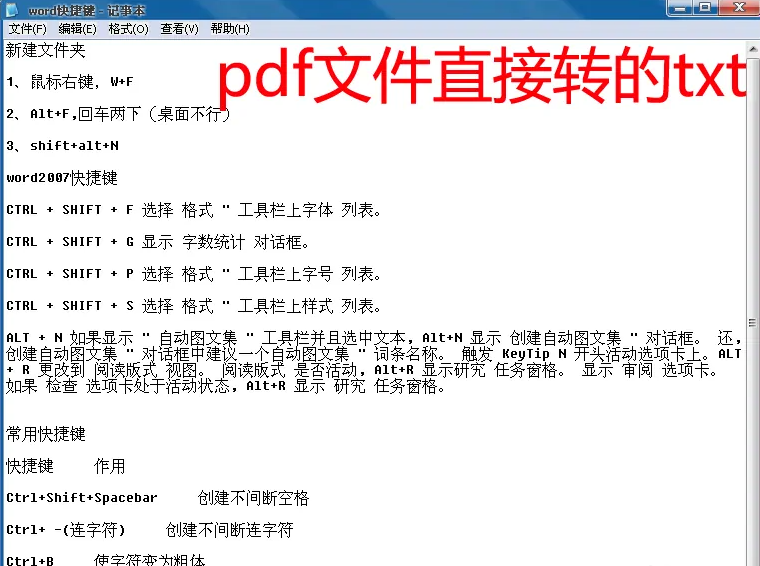
3、在弹出的打开图像文件中,直接选中PDF文件,此时下方的“pdf转换为TXT文件”将由灰变黑为可操作,点击该处,即可直接导出txt文件,但是此种方法针对PDF文件质量很高的情况,文件质量不高直接采用此种方法,误差率很高。
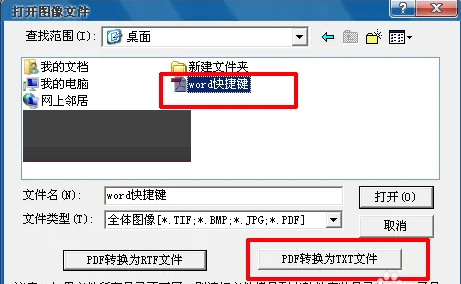
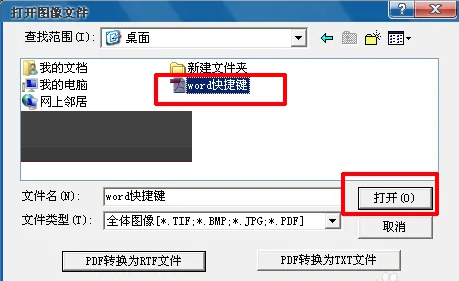
4、在PDF文件质量不高的情况下,直接选中pdf文件,点击“打开”。
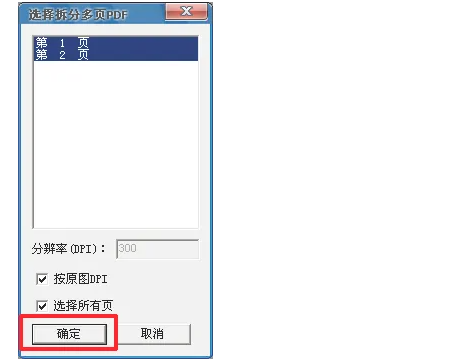
5、如果该pdf文件有多页,将会弹出“选择拆分多页PDF”,选择需要复制文字的页数(亦可先全选),点击确定。
6、打开后,在文件栏出现该文件,在界面下方框显示PDF文件该页具体情况。
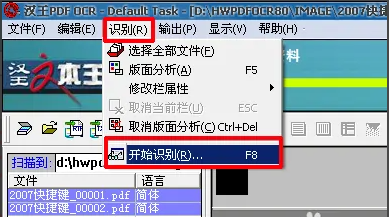
7、选中文件栏需要转换的该页PDF文件后(或全选),在工具栏点击“识别”-“开始识别”(或直接按F8)。
8、此时,在界面上方框显示正在识别,识别完成后,在界面上方框显示识别结果,此时,PDF文件质量不高的情况下会有一些错误,可手动修正即可。
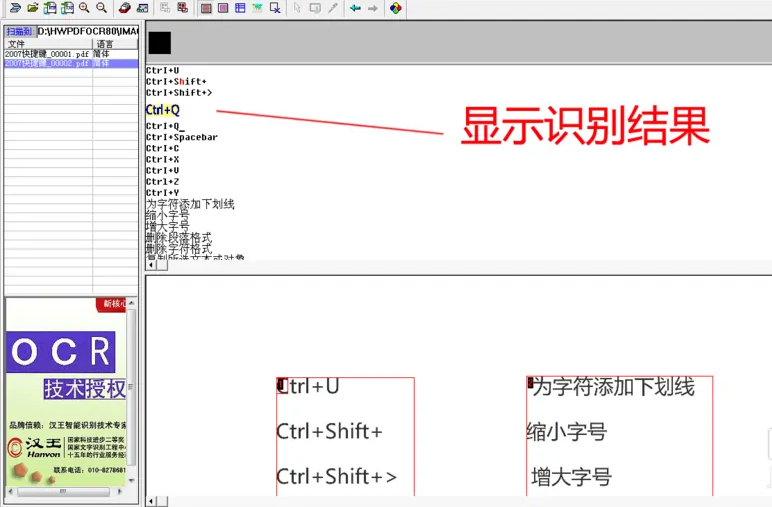
9、在界面上方框显示识别结果处,选中需要复制的文字,点击鼠标右键,选择,复制即可粘贴使用。